Introduction
Since I am a big fan of metal music (among other genres), one of my favorite websites is Metal-Archives, a website that maintains a very comprehensive database of metal bands from all over the world, as well as the albums they released, the names of the band members that contributed to those albums, who created the artwork, who produced which albums etc. Additionally, the users of the website are also able to rate the albums on a scale from 0-100%.
Despite Metal-Archives being a great website to find new metal albums to listen to, I wanted to be able to order by album rating while searching their music database, to filter out the less interesting albums, which is not possible as of right now. I know that highly rated albums are not necessarily fantastic (and that badly rated albums are not necessarily terrible), but if an album has as large number of high ratings, it may at least be worth checking out.
Web scraping
Since ordering by rating was not possible, I decided to build a web scraper, which would allow me to store the data from the Metal-Archives in my own database, allowing me to query it in whatever way I want to. A web scraper is simply put a piece of software that traverses web pages, and (typically) extracts data from those pages automatically.
While standard scraping is usually quite simple in Python (by using packages such as requests to retrieve the web page's HTML and BeautifulSoup to parse the HTML to extract the interesting data from it), it required a little bit more work to scrape the data from Metal-Archives. This was due to the fact that the data is displayed dynamically, with JavaScript, and it is not possible to retrieve this data with a simple HTTP request. In order to fix this issue, a web browser must be simulated, allowing the JavaScript generated content to load properly. The downside to this approach is that it significantly slows down the scraping process. I chose to use Selenium for this web browser simulation.
By using Selenium, I created a scraper that, for a given list of countries of origin, extracts all of the albums with a rating above a threshold (i.e. 85%) for all of the bands from those countries, and stores the results in a MySQL database on my local machine.
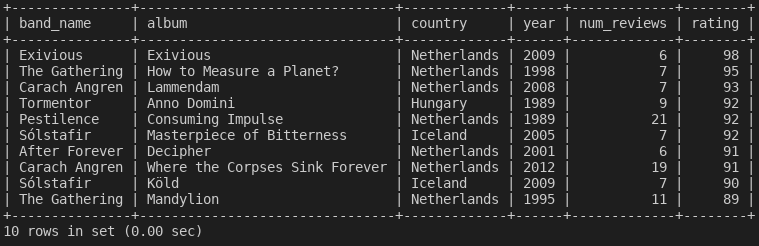
For instance, if I want to show the 10 albums with the greatest total rating by bands from the countries Iceland, Hungary and the Netherlands with at least 5 reviews, I could execute the following SQL query in mysql:
mysql> SELECT band_name, album, country, year, num_reviews, rating FROM albums WHERE num_reviews > 5 AND country in ('Netherlands', 'Iceland', 'Hungary') ORDER BY rating DESC LIMIT 10;
The following results appear would appear in my terminal: